⚠️️ 整理自互联网,用于概念了解。
Redis 是什么
Redis(Remote Dictionary Server)是一种基于内存的数据库,对数据的读写操作都是在内存中完成,因此读写速度非常快,常用于缓存, 消息队列、分布式锁等场景。并且,Redis 存储的是 KV 键值对数据,为了满足不同的业务场景,Redis 内置了多种数据类型实现。并且 Redis 还支持事务、持久化、Lua 脚本、发布订阅模型、内存淘汰机制、过期删除机制等等。
Redis 常见数据类型
更多常用命令查询见 Redis 命令手册。
String
String 是最基本的 key-value 结构,key 是唯一标识,value 是具体的值。
value 可以是字符串,也可以是数字(整数或浮点数),value 最多可以容纳的数据长度是 512M。
List
List 是简单的字符串列表,按照插入顺序排序,可以从头部或尾部向 List 列表添加元素。
列表的最大长度为 2^32-1,即每个列表支持超过 40 亿个元素。
常用指令
# 将一个或多个值 value 插入到 key 列表的表头(最左边),最后的值在最前面
LPUSH key value [value ...]
# 将一个或多个值 value 插入到 key 列表的表尾(最右边)
RPUSH key value [value ...]
# 移除并返回 key 列表的头元素
LPOP key
# 移除并返回 key 列表的尾元素
RPOP key
# 返回列表 key 中指定区间内的元素,区间以偏移量 start 和 stop 指定,从 0 开始
LRANGE key start stop
# 从 key 列表表头弹出一个元素,没有就阻塞 timeout 秒,如果 timeout=0 则一直阻塞
BLPOP key [key ...] timeout
# 从 key 列表表尾弹出一个元素,没有就阻塞 timeout 秒,如果 timeout=0 则一直阻塞
BRPOP key [key ...] timeout
Hash
Hash 是一个键值对 key-value 集合,特别适合用于存储对象。
其中 value 的形式如:value=[{field1, value1},{fieldN, valueN}]。
常用指令
# 存储一个哈希表 key 的键值
HSET key field value
# 获取哈希表 key 对应的 field 键值
HGET key field
# 在一个哈希表 key 中存储多个键值对
HMSET key field value [field value ...]
# 批量获取哈希表 key 中多个 field 键值
HMGET key field [field ...]
# 删除哈希表 key 中的 field 键值
HDEL key field [field ...]
# 返回哈希表 key 中 field 的数量
HLEN key
# 返回哈希表 key 中所有的键值
HGETALL key
# 为哈希表 key 中 field 键的值加上增量 N
HINCRBY key field N
Set
Set 类型是一个无序并唯一的键值集合,它的存储顺序不会按照插入的先后顺序进行存储。
一个集合最多可以存储 2^32-1 个元素。概念和数学中个的集合基本类似,可以交集,并集,差集等等,所以 Set 类型除了支持集合内的增删改查,同时还支持多个集合取交集、并集、差集。
常用指令
# 往集合 key 中存入元素,元素存在则忽略,若 key 不存在则新建
SADD key member [member ...]
# 从集合 key 中删除元素
SREM key member [member ...]
# 获取集合 key 中所有元素
SMEMBERS key
# 获取集合 key 中的元素个数
SCARD key
# 判断 member 元素是否存在于集合 key 中
SISMEMBER key member
# 从集合 key 中随机选出 count 个元素,元素不从 key 中删除
SRANDMEMBER key [count]
# 从集合 key 中随机选出 count 个元素,元素从 key 中删除
SPOP key [count]
# 交集运算
SINTER key [key ...]
# 将交集结果存入新集合 destination 中
SINTERSTORE destination key [key ...]
# 并集运算
SUNION key [key ...]
# 将并集结果存入新集合 destination 中
SUNIONSTORE destination key [key ...]
# 差集运算
SDIFF key [key ...]
# 将差集结果存入新集合 destination 中
SDIFFSTORE destination key [key ...]
ZSet(Sorted Set)
ZSet类型(有序集合类型)相比于 Set 类型多了一个排序属性 score(分值),对于有序集合 ZSet 来说,每个存储元素相当于有两个值组成的,一个是有序集合的元素值,一个是排序值。
有序集合保留了集合不能有重复成员的特性(分值可以重复),但不同的是,有序集合中的元素可以排序。
常用指令
# 往有序集合 key 中加入带分值元素
ZADD key score member [[score member]...]
# 往有序集合 key 中删除元素
ZREM key member [member...]
# 返回有序集合 key 中元素 member 的分值
ZSCORE key member
# 返回有序集合 key 中元素个数
ZCARD key
# 为有序集合 key 中元素 member 的分值加上 increment
ZINCRBY key increment member
# 正序获取有序集合 key 从 start 下标到 stop 下标的元素
ZRANGE key start stop [WITHSCORES]
# 倒序获取有序集合 key 从 start 下标到 stop 下标的元素
ZREVRANGE key start stop [WITHSCORES]
# 返回有序集合中指定分数区间内的成员,分数由低到高排序
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset Count]
# 返回指定成员区间内的成员,按字典正序排列,分数必须相同
ZRANGEBYLEX key min max [LIMIT offset count]
# 返回指定成员区间内的成员,按字典倒序排列,分数必须相同
ZREVRANGEBYLEX key max min [LIMIT offset count]
# 并集计算(相同元素分值相加)
ZUNIONSTORE destkey numberkeys key [key...]
# 交集计算(相同元素分值相加)
ZINTERSTORE destkey numberkeys key [key...]
Bitmap
Bitmap 位图是一串连续的二进制数组,可以通过偏移量 OFFSET 来定位元素。BitMap 通过最小的单位 Bit 来进行 0 或 1 的设置,表示某个元素的值或者状态,时间复杂度为 O(1)。
由于 Bit 是计算机中最小的单位,使用它进行储存将非常节省空间,特别适合一些数据量大且使用二值统计的场景。
常用指令
# 设置位值,其中 value 只能是 0 和 1
SETBIT key offset value
# 获取位值
GETBIT key offset
# 获取指定范围内值为 1 的个数
BITCOUNT key start end
# destkey 计算的结果,会存储在该 key 中
# key1 ... keyN 参与运算的key,可以有多个,空格分割,NOT 运算只能一个 key
# 当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作 0
# 返回值是保存到 destkey 的字符串的长度,和输入 key 中最长的字符串长度相等。
#
# operations 位移操作符,枚举值
# AND 与运算 &
# OR 或运算 |
# XOR 异或 ^
# NOT 取反 ~
BITOP [operations] [destkey] [key1] [keyN ...]
# 返回指定 key 中第一次出现指定 value(0 或 1)的位置
BITPOS [key] [value]
GEO
GEO 是 Redis 3.2 版本新增的数据类型,主要用于存储地理位置信息,并对存储的信息进行操作。
GEO 非常适合应用在基于位置的信息服务(Location-Based Service)场景中。LBS 应用访问的数据是和人或物关联的一组经纬度信息,而且要能查询相邻的经纬度范围。
常用指令
# 存储指定的地理空间位置,可以将一个或多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的 key 中。
GEOADD key longitude latitude member [longitude latitude member ...]
# 从给定的 key 里返回所有指定名称(member)的经度和纬度,不存在的返回 nil
GEOPOS key [member [member ...]]
# 返回两个给定位置之间的距离
GEODIST key member1 member2 [M | KM | FT | MI]
# 根据用户给定的经纬度坐标来获取指定范围内的地理位置集合
GEORADIUS key longitude latitude radius <M | KM | FT | MI>
[WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count [ANY]] [ASC | DESC]
[STORE key | STOREDIST key]
HyperLogLog
HyperLogLog 是 Redis 2.8.9 版本新增的数据类型,是一种用于统计基数的数据集合类型。
基数统计就是指统计一个集合中不重复的元素个数。但要注意,HyperLogLog 是统计规则是基于概率完成的,不是非常准确,简单来说 HyperLogLog 提供不精确的去重计数。
HyperLogLog 的优点是在输入元素的数量或者体积非常非常大时,计算基数所需的内存空间总是固定的、并且是很小的。在 Redis 里面,每个 HyperLogLog 键只需要花费 12KB 内存,就可以计算接近 2^64 个不同元素的基数,和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 非常节省空间。
常用指令
# 添加指定元素到 HyperLogLog 中
PFADD key element [element ...]
# 返回给定 HyperLogLog 的基数估算值
PFCOUNT key [key ...]
# 将多个 HyperLogLog 合并为一个 HyperLogLog
PFMERGE destkey sourcekey [sourcekey ...]
Stream
Stream 是 Redis 5.0 版本新增加的数据类型,是 Redis 专门为消息队列设计的数据类型。
在 Redis Stream 没出来之前,消息队列的实现方式都有着各自的缺陷,例如:
- 发布订阅模式,不能持久化也就无法可靠的保存消息,并且对于离线重连的客户端不能读取历史消息。
- List 实现消息队列的方式不能重复消费,一个消息消费完就会被删除,而且生产者需要自行实现全局唯一 ID。
基于以上问题,Redis 5.0 推出了 Stream 类型,用于完美地实现消息队列。它支持消息的持久化、支持自动生成全局唯一 ID、支持 ACK 确认消息的模式、支持消费组模式等,让消息队列更加的稳定和可靠。
相关问题
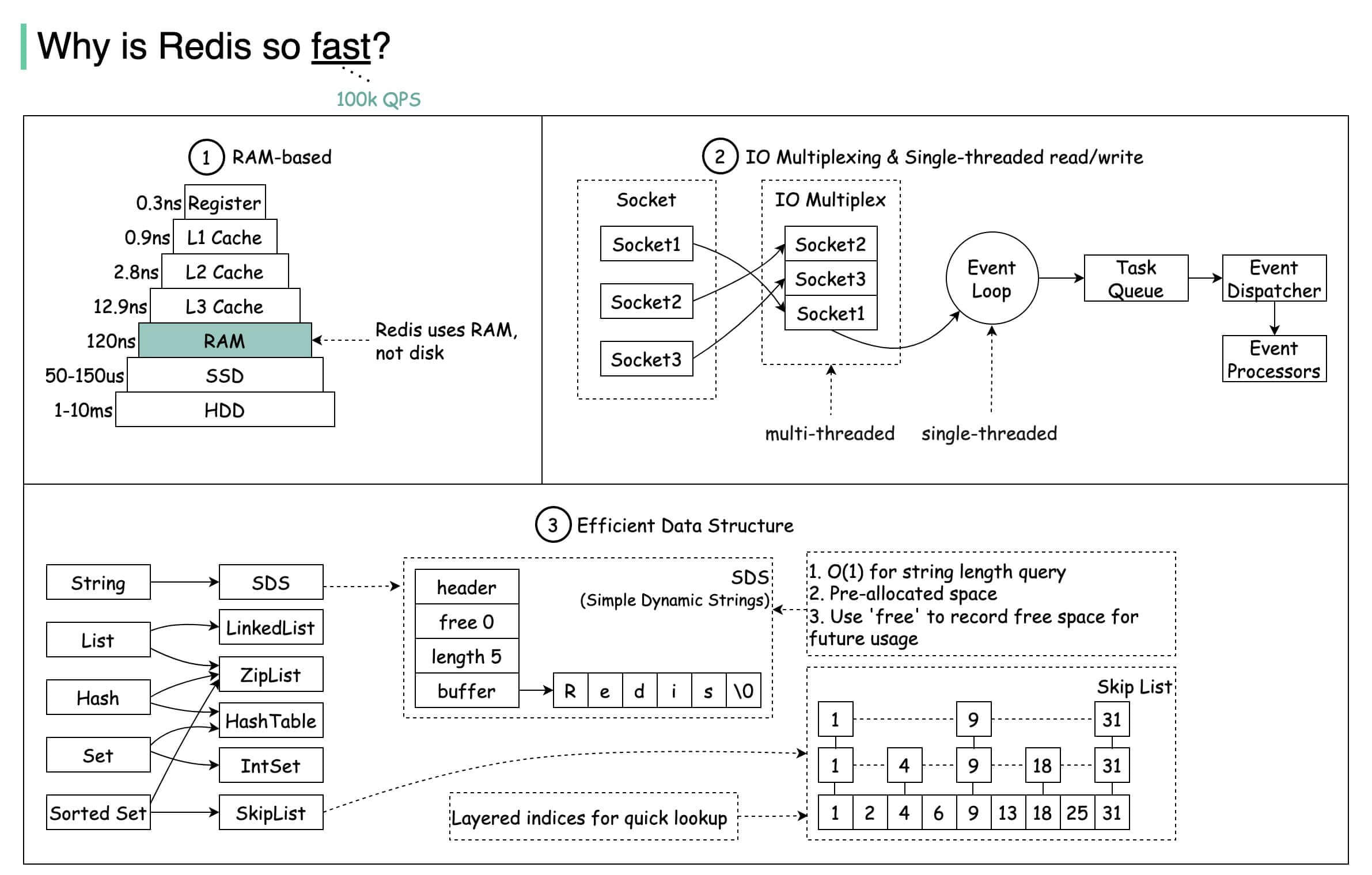
Redis 为什么这么快?
Redis 内部做了非常多的性能优化,比较重要的有下面 4 点:
- Redis 基于内存,内存的访问速度比磁盘快很多;
- Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型,主要是单线程事件循环和 IO 多路复用;
- Redis 内置了多种优化过后的数据类型和结构实现,性能非常高;
- Redis 通信协议实现简单且解析高效。
Redis 和 Memcached 的区别和共同点?
共同点:
- 都是基于内存的数据库,一般都用来当做缓存使用。
- 都有过期策略。
- 两者的性能都非常高。
区别:
-
数据类型:Redis 支持更丰富的数据类型和更复杂的应用场景。
- Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list、set、zset、hash 等数据结构的存储;
- 而 Memcached 只支持最简单的 k/v 数据类型。
-
数据持久化:Redis 支持数据的持久化。
- Redis 可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用;
- Memcached 把数据全部存在内存之中。
-
集群模式支持:Redis 原生支持集群模式。
- Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;
- Redis 自 3.0 版本起是原生支持集群模式的。
-
线程模型:
- Memcached 是多线程、非阻塞 IO 复用的网络模型;
- Redis 使用单线程的多路 IO 复用模型(Redis 6.0 针对网络数据的读写引入了多线程)。
-
特性支持:
- Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。
- 过期数据删除:Memcached 过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。
Redis 除了做缓存还有哪些应用场景?
-
分布式锁:通过 Redis 来做分布式锁是一种比较常见的方式。
-
限流:通过 Redis + Lua 脚本的方式实现限流。
-
消息队列:
- Redis 自带的 List 数据结构可以作为一个简单的队列使用。
- Redis 5.0 中增加的 Stream 类型更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
-
分布式 Session:利用 String 或者 Hash 数据类型保存 Session 数据。
-
复杂业务场景:通过 Redis 以及 Redis 扩展可以很方便地完成很多复杂的业务场景。
- 通过 Bitmap 统计活跃用户、
- 通过 Sorted Set 维护排行榜、
- 通过 HyperLogLog 统计网站 UV 和 PV。
Redis 如何保障操作的原子性?
Redis 通过其独特的单线程模型和精心设计的功能来保障操作的原子性,单线程模型在其中起到了基础性和核心性的作用。
Redis 使用一个单线程(主线程)来处理所有来自客户端的命令请求。这意味着在任何给定的时刻,只有一个命令在被 Redis 服务器执行。由于单线程顺序执行命令,Redis 的每个命令本身都是原子操作。