InnoDB 的索引模型

根据叶子节点的内容,索引类型分为主键索引和非主键索引。
- 主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。
- 非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。
B+ 树和数据页
InnoDB 的数据是按数据页为单位来读写的,默认数据页大小为16 KB。每个数据页之间通过双向链表的形式组织起来,物理上不连续,但是逻辑上连续。
InnoDB 使用 B+ 树作为索引,B+ 树中的每个节点都是一个数据页,结构示意图如下:
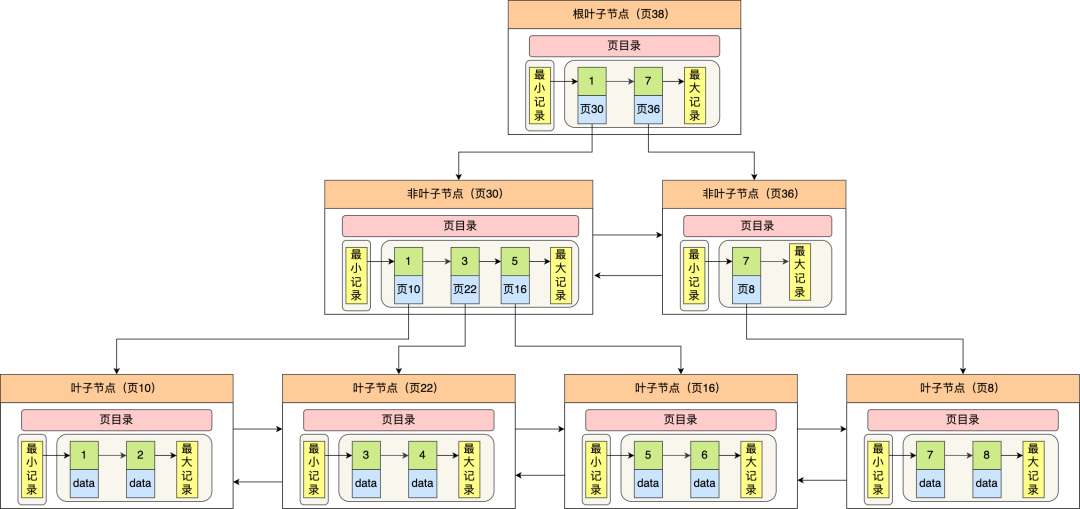 「图片来自 小林 Coding」
「图片来自 小林 Coding」
回表和覆盖索引
用表 T(id, k),id 为主键索引,k 为非主键索引,来举例分析:
-
通过主键索引查询方式,如
SELECT * FROM T WHERE id = ?只需要搜索 id 这棵 B+ 树; -
通过非主键索引查询方式,如
SELECT * FROM T WHERE k = ?则需要先搜索 k 索引树,得到 id 的值,再到 id 索引树搜索一次。这个过程称为『回表』。 -
如果执行的语句是
SELECT id FROM T WHERE k = ?,这时只需要查 id 的值,而 id 的值已经在 k 索引树上了,因此可以直接提供查询结果,不需要回表,这个过程称为『覆盖索引』。
由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
最左前缀原则
当使用联合索引进行查询时,MySQL 可以利用该索引的最左前缀(最左边的一个或多个列)来加速查询。查询条件必须包含索引定义中从左到右的连续列,不能跳过中间列。
关键点:
- 连续性:必须是从左开始的连续列。
- 范围查询:如果某个列使用了范围查询 (
>, <, BETWEEN, LIKE),则该列右边的所有列都无法再使用索引进行进一步的精确查找或排序,索引只能利用到该范围列之前(包括该范围列本身)的列。 - 排序:ORDER BY 子句同样遵循最左前缀原则。
- 顺序:对于联合索引 (A,B,C) 来说,查询语句中的顺序可以是
WHERE B=? AND C=? AND A=?,MySQL 优化器会重新组织 WHERE 条件并重排,使其尽可能高效地使用索引。
索引下推
索引下推(Index Condition Pushdown)是 MySQL 5.6 版本引入的一项查询优化技术 ,主要用于优化使用非主键索引(二级索引)的查询过程。其核心思想是:将原本需要在 MySQL 服务器层处理的部分查询条件,下推到存储引擎层(如 InnoDB)在索引扫描阶段提前过滤数据,从而减少不必要的回表操作和数据传输量。
例如,对于联合索引 (A,B,C),查询语句 WHERE A=? AND C=? 来说,根据最左前缀原则,联合索引只能利用到 A 列:
- 在 MySQL 5.6 之前,C 列的等值查询会被忽略,需要回表操作后再去判断。
- MySQL 5.6 引入的索引下推优化,可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
相关问题
InnoDB 表无主键的情况下数据是如何存储的?
在 InnoDB 存储引擎中,每个表都必须有一个主键,即使在没有显式定义主键的情况下,InnoDB 也会通过以下机制自动选择或生成一个主键来组织数据存储:
- 如果表中存在一个非空的唯一索引(UNIQUE NOT NULL),InnoDB 会将其作为主键使用,而不会额外创建隐藏列。
- 如果表中既没有显式定义主键,也没有非空的唯一索引,InnoDB 会为表自动添加一个名为 row_id 的隐藏列作为主键。
数据始终以主键为依据,存储在聚簇索引的 B+ 树中。显式定义主键是更优的实践,可避免潜在的性能问题。
InnoDB B+ 索引树节点的键值是如何排序的?
不同字段类型的索引的排序规则由其数据类型和字符集排序规则决定:
- 对于数值类型字段,如int,比较大小很简单,直接数值比较。
- VARCHAR 类型字段的非主键索引树通过『字符集排序规则』来区分大小。
- 日期或时间类型(如 DATE、DATETIME):按时间先后排序。
- 二进制类型(如 BLOB):按字节的二进制值排序。
对于联合索引的排序,首先按第一个字段 的排序规则进行整体排序;当第一个字段值相同时,再按第二个字段 的排序规则排序;依此类推,直到所有索引字段都参与排序。
索引失效有哪些情况?

- 不符合联合索引的非最左匹配原则。
- 对索引字段使用左或者左右模糊匹配(
LIKE %xx或者LIKE %xx%)。因为 B+ 索引树是按照索引值有序排列存储的,只能根据前缀进行比较。 - 对索引字段使用函数(从 MySQL 8.0 开始,索引特性增加了函数索引,可以针对函数计算后的值建立一个索引,就可以通过扫描索引来查询数据)。
- 对索引字段进行表达式计算。
- 对索引字段隐式类型转换。MySQL 遇到字符串和数字比较的时候,会自动把字符串转为数字,然后再进行比较。如果字符串是索引列,而条件语句中的输入参数是数字的话,那么索引列会发生隐式类型转换,由于隐式类型转换是通过 CAST 函数实现的,等同于对索引列使用了函数,所以就会导致索引失效。
- WHERE 子句中的 OR,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效。
- 对索引字段使用 NOT 或 !=。
- 数据量过少时优化器放弃使用索引。
MySQL Explain 执行计划结果解析?

内容摘抄自 JavaGuide,原文链接。
mysql> EXPLAIN SELECT * FROM T WHERE id = 1;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | T | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.000 sec)
可以看到,执行计划结果中共有 12 列,各列代表的含义总结如下表:
| 列名 | 含义 |
|---|---|
| id | SELECT 查询的序列标识符 |
| select_type | SELECT 关键字对应的查询类型 |
| table | 用到的表名 |
| partitions | 匹配的分区,对于未分区的表,值为 NULL |
| type | 表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际用到的索引 |
| key_len | 所选索引的长度 |
| ref | 当使用索引等值查询时,与索引作比较的列或常量 |
| rows | 预计要读取的行数 |
| filtered | 按表条件过滤后,留存的记录数的百分比 |
| Extra | 附加信息 |
id
SELECT 标识符,用于标识每个 SELECT 语句的执行顺序。
id 如果相同,从上往下依次执行。id 不同,id 值越大,执行优先级越高,如果行引用其他行的并集结果,则该值可以为 NULL。
select_type
查询的类型,主要用于区分普通查询、联合查询、子查询等复杂的查询,常见的值有:
- SIMPLE:简单查询,不包含 UNION 或者子查询。
- PRIMARY:查询中如果包含子查询或其他部分,外层的 SELECT 将被标记为 PRIMARY。
- SUBQUERY:子查询中的第一个 SELECT。
- UNION:在 UNION 语句中,UNION 之后出现的 SELECT。
- DERIVED:在 FROM 中出现的子查询将被标记为 DERIVED。
- UNION RESULT:UNION 查询的结果。
table
查询用到的表名,每行都有对应的表名,表名除了正常的表之外,也可能是以下列出的值:
<union M,N>: 本行引用了 id 为 M 和 N 的行的 UNION 结果;<derived N>: 本行引用了 id 为 N 的表所产生的的派生表结果。派生表有可能产生自 FROM 语句中的子查询。<subquery N>: 本行引用了 id 为 N 的表所产生的的物化子查询结果。
type(重要)

查询执行的类型,描述了查询是如何执行的。所有值的顺序从最优到最差排序为:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
常见的几种类型具体含义如下:
- system:如果表使用的引擎对于表行数统计是精确的(如:MyISAM),且表中只有一行记录的情况下,访问方法是 system ,是 const 的一种特例。
- const:表中最多只有一行匹配的记录,一次查询就可以找到,常用于使用主键或唯一索引的所有字段作为查询条件。
- eq_ref:当连表查询时,前一张表的行在当前这张表中只有一行与之对应。是除了 system 与 const 之外最好的 join 方式,常用于使用主键或唯一索引的所有字段作为连表条件。
- ref:使用普通索引作为查询条件,查询结果可能找到多个符合条件的行。
- index_merge:当查询条件使用了多个索引时,表示开启了 Index Merge 优化,此时执行计划中的 key 列列出了使用到的索引。
- range:对索引列进行范围查询,执行计划中的 key 列表示哪个索引被使用了。
- index:查询遍历了整棵索引树,与 ALL 类似,只不过扫描的是索引,而索引一般在内存中,速度更快。
- ALL:全表扫描。
possible_keys
possible_keys 列表示 MySQL 执行查询时可能用到的索引。如果这一列为 NULL,则表示没有可能用到的索引;这种情况下,需要检查 WHERE 语句中所使用的的列,看是否可以通过给这些列中某个或多个添加索引的方法来提高查询性能。
key(重要)
key 列表示 MySQL 实际使用到的索引。如果为 NULL 则表示未用到索引。
key_len
key_len 列表示 MySQL 实际使用的索引的最大长度;当使用到联合索引时,有可能是多个列的长度和。在满足需求的前提下越短越好。如果 key 列显示 NULL,则 key_len 列也显示 NULL。
rows
rows 列表示根据表统计信息及选用情况,大致估算出找到所需的记录或所需读取的行数,数值越小越好。
Extra(重要)
这列包含了 MySQL 解析查询的额外信息,通过这些信息,可以更准确的理解 MySQL 到底是如何执行查询的。常见的值如下:
- Using filesort:在排序时使用了外部的索引排序,没有用到表内索引进行排序。
- Using temporary:MySQL 需要创建临时表来存储查询的结果,常见于 ORDER BY 和 GROUP BY。
- Using index:表明查询使用了覆盖索引,不用回表,查询效率非常高。
- Using index condition:表示查询优化器选择使用了索引条件下推这个特性。
- Using where:表明查询使用了 WHERE 子句进行条件过滤。一般在没有使用到索引的时候会出现。
- Using join buffer:连表查询的方式,表示当被驱动表的没有使用索引的时候,MySQL 会先将驱动表读出来放到 join buffer 中,再遍历被驱动表与驱动表进行查询。
这里提醒下,当 Extra 列包含 Using filesort 或 Using temporary 时,MySQL 的性能可能会存在问题,需要尽可能避免。